

Neváhejte a napište
nám zprávu.

Představení MTA
event_note 06.05.2019
V dnešním příspěvku představíme náš MTA (Multicriterial Text Analysis) software. Produkt MTA uživatelům významně usnadňuje rozhodování v oblasti nakupování nejrůznějších produktů či služeb.
Motivace
Produkt si klade za cíl pomoci zákazníkům orientovat se ve velkém množství názorů publikovaných na internetu na konkrétní zboží nebo služby, které by si chtěli zakoupit nebo využít. Uživatelské recenze a hodnocení jsou rozesety na nejrůznějších diskusních fórech, webech pro hodnocení produktů či portálech zabývajících se konkrétní problematikou. Pro běžného uživatele je obtížné a časově náročné tyto informace vyhledat, zorientovat se v nich a udělat si vlastní názor.
MTA architektura
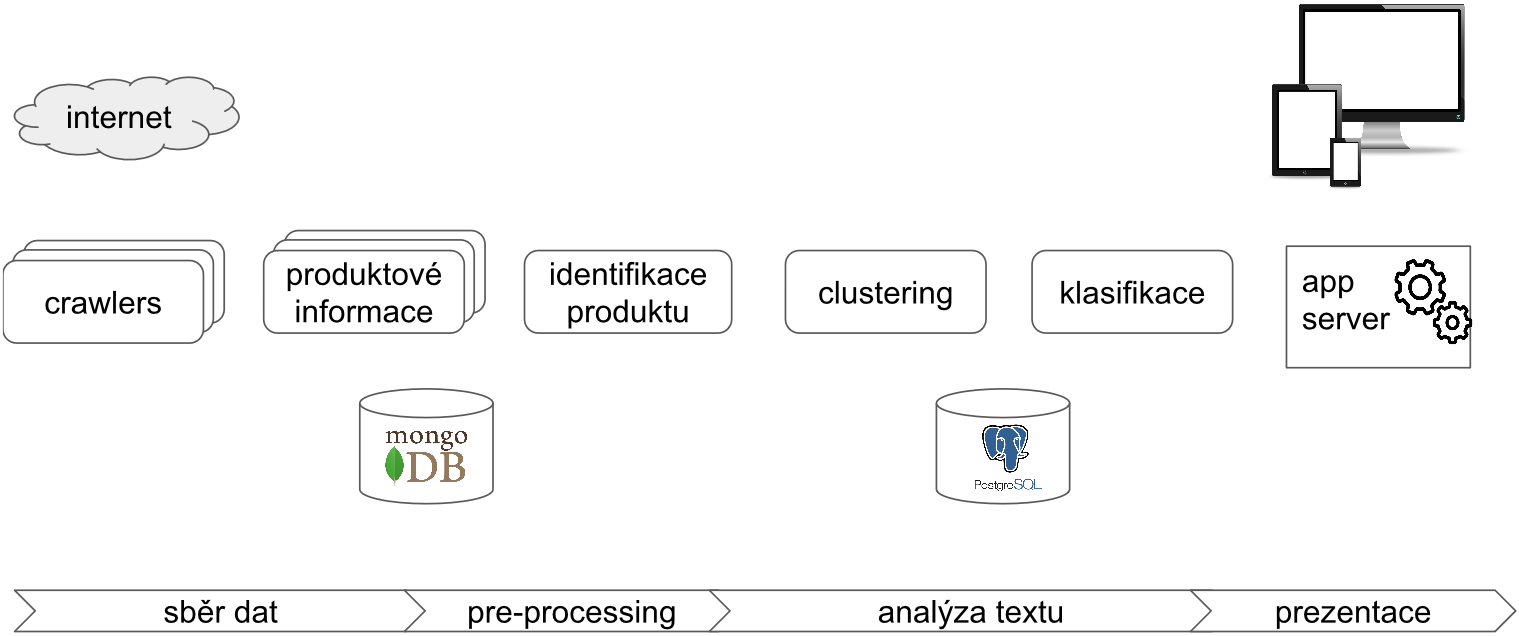
Sběr dat
Na sběr dat používáme sadu nástrojů (crawlery) pro stahování uživatelských recenzí a článků o vybrané skupině produktů nebo služeb. Tyto crawlery jsou přizpůsobeny struktuře definovaných webů a získávají z nich relevantní data, která mohou při analýze témat a postojů pomoci. Máme připravenou sadu crawlerů, pomocí nichž jsme už stáhli více než milion uživatelských recenzí.
Pre-processing
Při získávání dat čelíme obvykle několika problémům. Jeden z hlavních spočívá v různém způsobu označování produktů na různých webech. Přestože se jedná o identický produkt bývají v názvech odlišnosti, které identifikaci produktů komplikují. Např. produkt “Canon EOS 600D” se skrývá ve všech následujících prodejních názvech:
- “Zrcadlovka Canon EOS 600D”,
- “Canon EOS 600D SLR digitální kamera”,
- “Digitální fotoaparát Canon EOS 600D SLR (18 mpx, 7,6 cm (3″) otočný displej, Full HD”
- “Digitální zrcadlovka Canon EOS 600D (18 megapixelů, 7,6cm (3palcový) displej, APS-C CMOS senzor, WLAN s NFC, Full HD, Digic 7) kit vč. EF-S 18-55mm, 1:4,0 – 5,6 IS STM, černá”
Důležité je správně rozpoznat, které názvy identifikují stejný produkt a sjednotit k nim publikované recenze. V tomto procesu využíváme metod strojového učení.
Získané recenze je nezbytné dále upravit pro zjednodušení následné analýzy. Nejprve je nutné rozdělit je na jednotlivé větné celky, které obvykle obsahují samostatná témata. Následně upravujeme slova do základního tvaru a odstraňujeme diakritiku. Dále je vhodné odebrat slova, která nenesou požadovanou informační hodnotu (např. předložky, spojky, apod). K tomu využíváme jednak vlastní POS analyzátor, který přiřazuje slovům ve větě slovní druhy, a také dataset se stop slovy vytvořený vlastními silami.
Takto upravené dokumenty převedeme do do vektorového tvaru s využitím metodiky Tf-idf.
Analýza textu
Pro analýzu velkého množství nestrukturovaných dat využíváme metod strojového učení. Pomocí nich v datech identifikujeme nejvíce diskutovaná témata a určujeme pozitivní nebo negativní postoj recenzentů k jednotlivým vlastnostem produktů. Pomocí shlukovacích metod (k-means) rozdělujeme recenze do shluků se stejnými tématy. Daří se nám identifikovat shluky s vysokou mírou vnitřní integrity, kde se identifikovaná témata týkají hlavních parametrů zkoumaného segmentu produktů. Takto vytvořené shluky pro daný segment, založené na odborných článcích, dále používáme pro klasifikaci recenzí k jednotlivým produktům.
Prezentace výsledků
Nejjednodušší forma prezentace výsledků textové analýzy, kterou využíváme, je statický report. Tento výstup obsahuje názvy produktů, jejich diskutované vlastnosti a statistiku o tom, jak často jsou uvedené vlastnosti vnímané pozitivně respektive negativně.
Příklad
Nikon D850
pozitivní:
* vyborne rozliseni obrazoveho snimace,
* citlivost ostreni je vyborna,
* dobre se drzi ruce,
* bezkonkurencni kvalita obrazu,
* podsviceni zadnich tlacitek,
* 4k uhd video 1920 x 1080 / zpomaleni zaznamu,
* nikon d850 me mile prekvapil,
* vyborne zvladnuty sum hodnoty 6400,
* ergonomie.
negativní:
* cena,
* velka spotreba gb,
* prodrazi optice,
* vyuziti potencialu je potreba mit primerene kvalitni optiku coz znamena nejlepsi mani,
* cena kvalita neni zadarmo.
Aktuálně připravujeme interaktivní webovou aplikaci spolu s aplikací pro mobilní zařízení.
Současně bude dostupné také API s pravidelně aktualizovanými údaji, pro snadnou integraci do již existujících řešení.
Pro další informace nebo poskytnutí zpětné vazby nás neváhejte kontaktovat.
Jan Přichystal
