

Feel free to write us
a message.

MTA Introduction
event_note 06.05.2019
In today’s post, we will introduce our MTA (Multicriterial Text Analysis) software. The MTA product significantly helps users with decisions in the area of shopping for various products and services.
Motivation
The product aims to help users get their head around the large amounts of opinions published on the internet on specific goods or services which they would like to buy or use. User reviews and ratings are scattered on various discussion forums, product review websites and portals dedicated to specific areas. It is difficult and time-consuming for an ordinary user to look up this information, familiarise with it and make own opinion on it.
MTA architecture
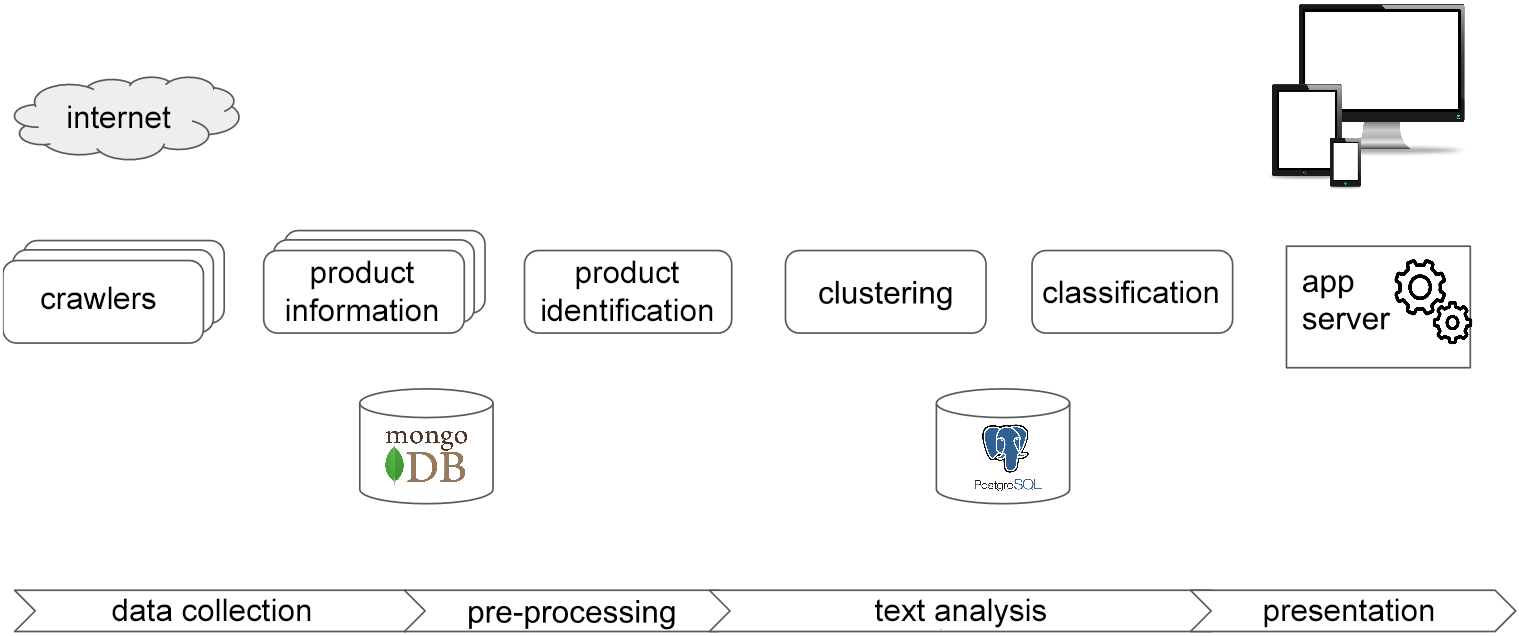
Data Collection
To collect data, we use a set of tools (crawlers) to download user reviews and articles about the selected group of products or services. These crawlers are adjusted to the structure of defined websites from which they collect relevant data that can be helpful for analysis of topics and sentiments. We have a set of crawlers through which we have already downloaded more than a million user reviews.
Pre-processing
When collecting data, we usually face several problems . One of the biggest ones is related to varied ways of naming products on different websites. Even though it is an identical product, there are distinctions in the name, which makes the product identification complicated. For instance, the product “Canon EOS 600D” is listed in all of the following sales names:
- “DSLR Canon EOS 600D camera”,
- “Canon EOS 600D SLR digital camera”,
- “Digital camera Canon EOS 600D SLR (18 mpx, 7,6 cm (3″) flip screen, Full HD”
- “Digital DSLR camera Canon EOS 600D (18 megapixels, 7,6cm (3inches) display, APS-C CMOS sensor, WLAN with NFC, Full HD, Digic 7) kit incl. EF-S 18-55mm, 1:4,0 – 5,6 IS STM, black”
It is important to correctly recognise which names identify the same product and connect the product published reviews. We use methods of machine learning in this process.
For further analysis, it is necessary to modify the obtained reviews. The first step is to divide them into individual sentences which usually include independent topics. Furthermore, we transform words into their basic form and remove diacritics. Additionally, it is beneficial to remove words which do not bare any required information value (such as prepositions, conjunctions etc.). To do this, we use our own POS analyser which assigns the word class to words in the sentence and we also use a dataset with stop words created by our own means. Documents edited this way are transformed into vector form, using Tf-idf methodology.
Text Analysis
To analyse large amounts of unstructured data, we use methods of machine learning. Using these, we identify the most discussed topics in the data and we determine reviewers’ positive or negative sentiment towards individual features of the products. Using cluster methods (k-means), we divide reviews into clusters with the same topics. We are able to successfully identify clusters with a high degree of internal integrity where identified topics highly correlate with main parameters of the examined product segment. These clusters, created for a particular segment, based on professional articles, are further used to classify reviews of the individual products.
Results Presentation
The easiest way how we present results of text analysis is a static report. This output includes product names, their discussed features and statistics on how often are the listed features perceived positively or negatively.
Example
Nikon D850
positive:
* excellent image sensor resolution,
* excellent focus sensitivity,
* comfortable grip,
* unrivalled image quality,
* rear buttons backlit,
* 4k uhd video 1920 x 1080 / record slow motion,
* pleasantly surprised with nikon d850,
* well-managed noise level 6400,
* ergonomics.
negative:
* price,
* gb high consumption,
* more expensive lenses,
* in order to utilise potential, it’s necessary to have adequate lenses, which means the best ones available,
* price quality doesn’t come cheap.
We are currently developing an interactive website application as well as an app for mobile devices. At the same time, for easy integration into already existing solutions, there will be API with regularly updated data.
Do not hesitate to contact us for more information or to provide us with feedback.
Jan Přichystal
