

Neváhejte a napište
nám zprávu.
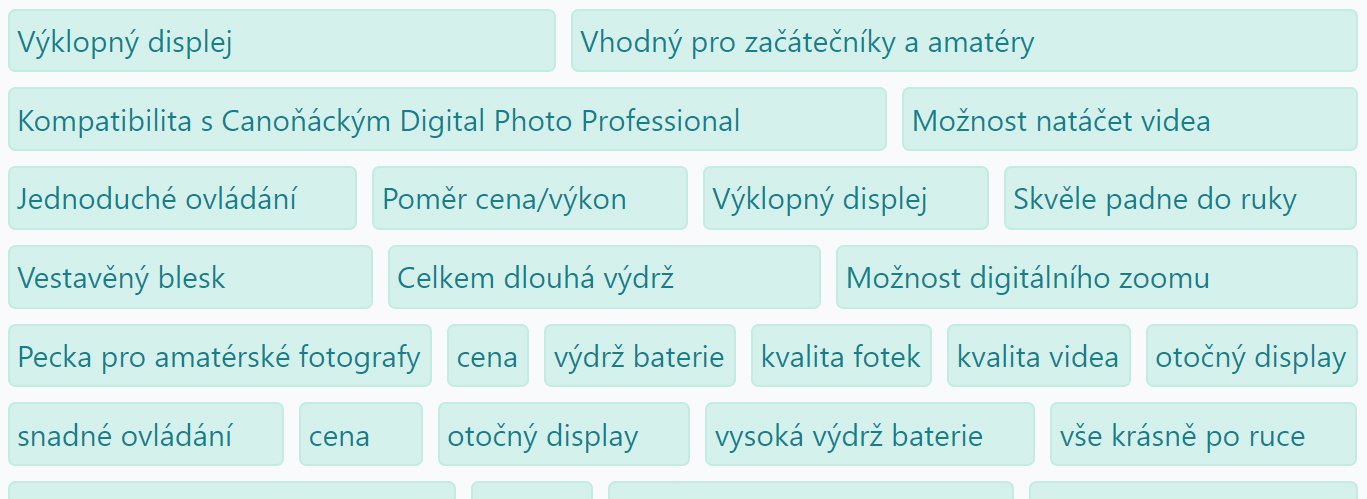
Suitable representatives for a set of reviews
event_note 08.01.2019
As we mentioned in the previous post, our team is working on a project to help you make decisions about buying different products and services. We try to help users create an objective view of the specific items they want to buy by analyzing published reviews of other users. Currently, we’ve downloaded enough reports and product articles in Czech and English language to analyze individual views. In the first phase it was necessary to adapt the obtained texts to the form suitable for analysis.
It was necessary to divide the documents into individual sentences, because users often present more ideas in one document and evaluate more criteria. The next step was to remove insignificant words that do not bring any or just little information value. For example, clutches, prepositions, web addresses, and so on. In this step, we also used our own POS analyzer, which assigns the words in sentence word types, and our own dataset with stop words. In particular, nouns, adjectives and verbs were interesting for us. Subsequently, we worded the words into their basic shapes, by specifying the roots of words.
We have transformed the edited documents into vector shape using tf-ifd and then split them into clusters with the same themes using k-means methods. We have managed to identify approximately diversified clusters with a high degree of internal integrity. Identified topics were related to the main parameters of the product segment surveyed.
The clusters created for the whole segment, based on expert articles, were then used to classify product reviews. From identified clusters for individual reviews, we chose those with the highest predictive value – and are presented as a suitable representative for a given set of reviews. The result of the analysis is shown in the example below.
Jan Přichystal
