

Neváhejte a napište
nám zprávu.

Database Creation and Text Analysis in Services
event_note 10.01.2019
Our EQS software, based on the text analysis in services (e.g. “I am looking for a nursery in Brno which takes children as young as 1 year old”), will present the user with appropriate suppliers.
To correctly pair the data, the search algorithm requires a sufficient amount of data for learning. We have approached this problem by creating web crawlers owing to which we received needed data in the Czech language from external sources. However, predominantly, we are creating our own database of all activities located in the Czech Republic.
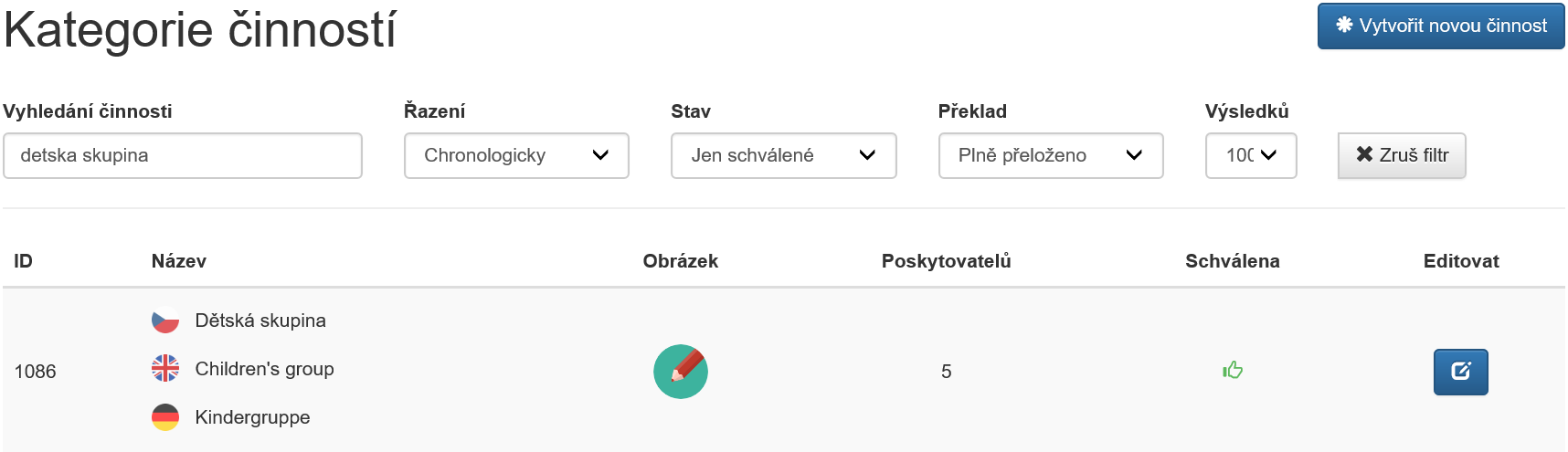
When creating it, we did not want to be limited only to the set of services (for example, the mentioned nursery or children’s group), nor occupations (teacher, nanny, …) but the aim was to create a complete database of all activities which people can possibly perform. For this reason, we merged mentioned areas and supplemented them with additional activities (for example, “babysitting”, or more detailed “night-time babysitting”).
The primary input for creating the database was the “National System of Occupations” which was further extended by categories from commercial enquiry servers. In this way, we created database areas, or more precisely, type clusters teacher/nanny/teacher assistant (=occupation) + nursery/children’s group (=service) + babysitting/children’s programme (=activity). We collectively refer to these categories as activities.
All activities were supplemented with keywords that are typical for them (children to nurseries, babysitting, …). Since our algorithm attaches the highest weight to keywords, these keywords are far more important than the names of the respective activities, therefore, the above-mentioned clusters are made by a set of words associated with the given activity/areas of activities.
When aggregating keywords, we used both automated and man-made databases and, last but not least, our own descriptions or suggestions of suppliers we have been calling to over the last 6 months to offer them a free presentation of their services on our test portal mojilidi.cz.
The primary database was afterwards published on the above-mentioned website and we started facing the real operation. The ones who were interested in the presentation of their services from any areas, entered a description of their activity to the search bar, for example, “We are running a children’s group in Brno which specialises in ABA therapy, speech therapy or exercising with kids.”
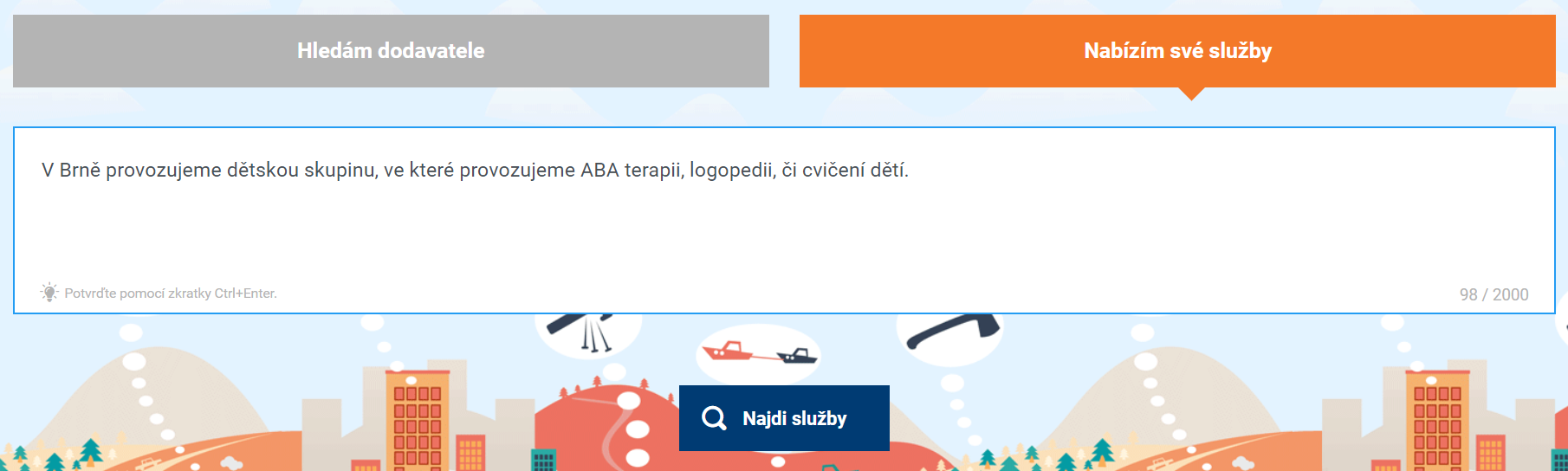
In response to the analysis of the input text, the users are presented with activities which are identified as most relevant (for example Children’s Group, Night Babysitting, Babysitting or wrongly Nutrition Therapist).
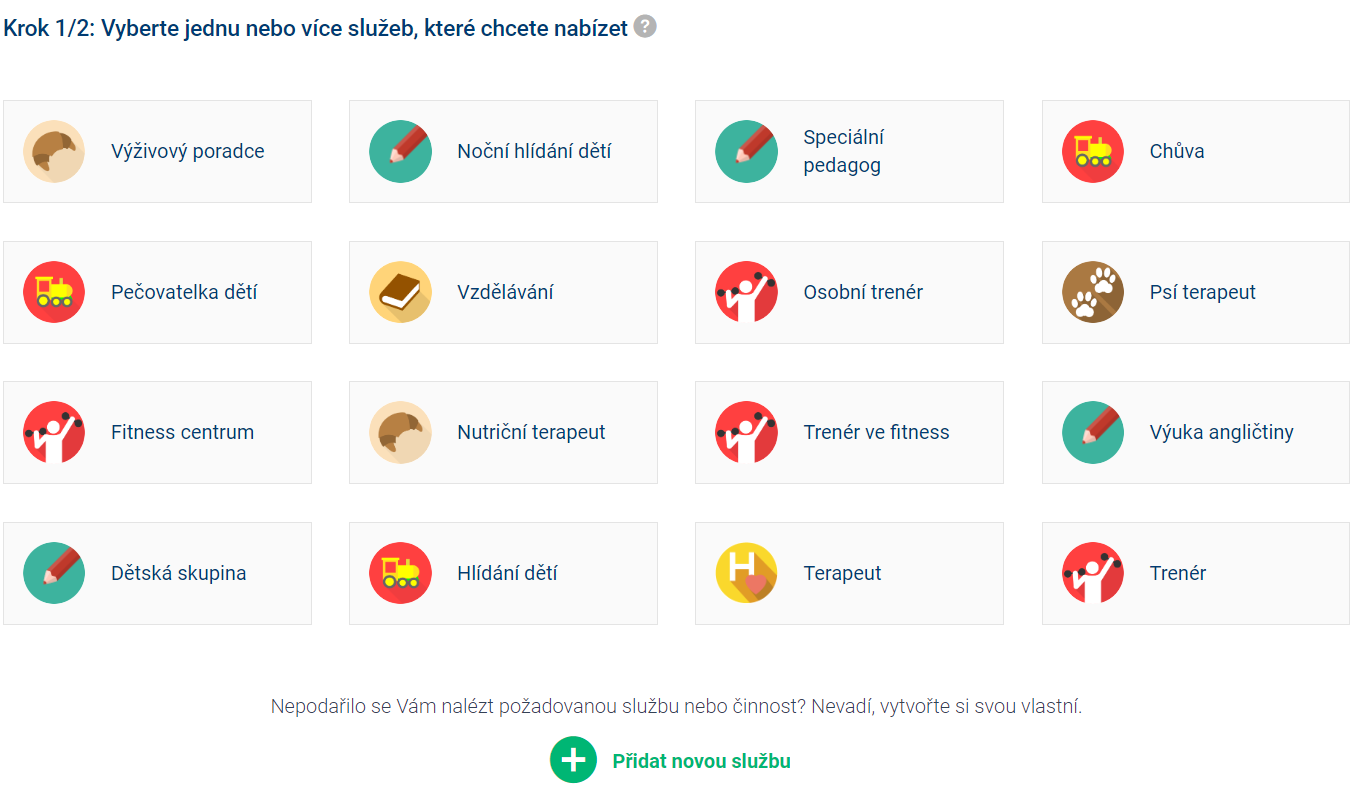
Users have an option either to apply to an already existing activity or to edit/add keywords and description regarding their services or add a completely new activity.
Adding a new activity is subject to confirmation by an administrator so that there are not double values such as taking care of a kid / taking care of kids. Considering the principles of the search algorithm, adding new similar activities would not be a problem. However, for tracking statistics or applying to an existing activity with the most relevant keywords, we are trying to approve only entirely new / not yet given activities.
By doing this, we have been complementing our own database over a year. Activities with a higher number of users have a database of the most interesting keywords and phrases which are recommended to users straight away at the registration.
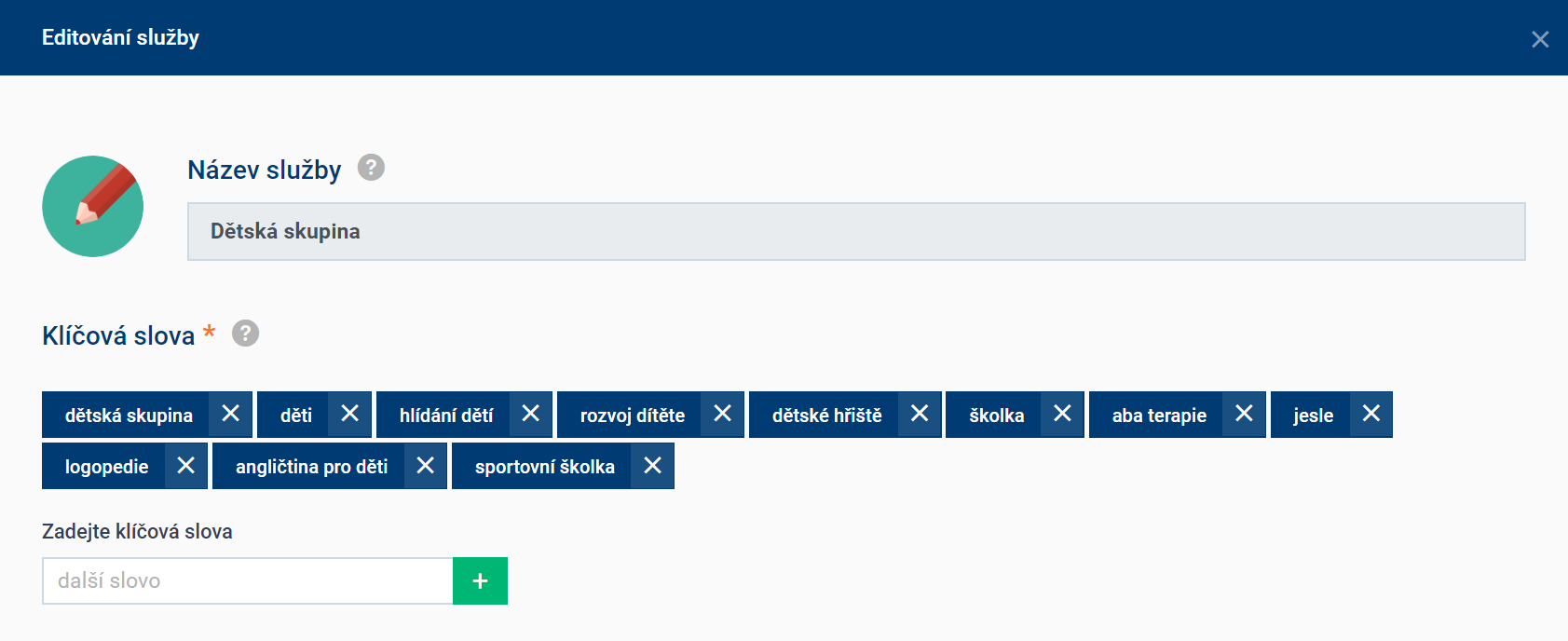
We also track which (and how many) activities include a particular keyword, see keywords listed above. Furthermore, we track the number of competition in individual regions. When comparing results gained from telephone calls with users and also by an analysis of new customers acquired from advertising in particular areas (for example, we are finding out that car repair shops are not interested in registering whereas text proofreaders are highly interested), interesting statistics about individual market segments are being developed.
The picture is related to Project Architect activity.
The database is constantly growing and updating with the ever-growing number of users. Likewise, our search algorithm is getting better and is offering more relevant results. In the following article, we are going to present how we translated our database into English and German and what interesting features have been accomplished by this.
